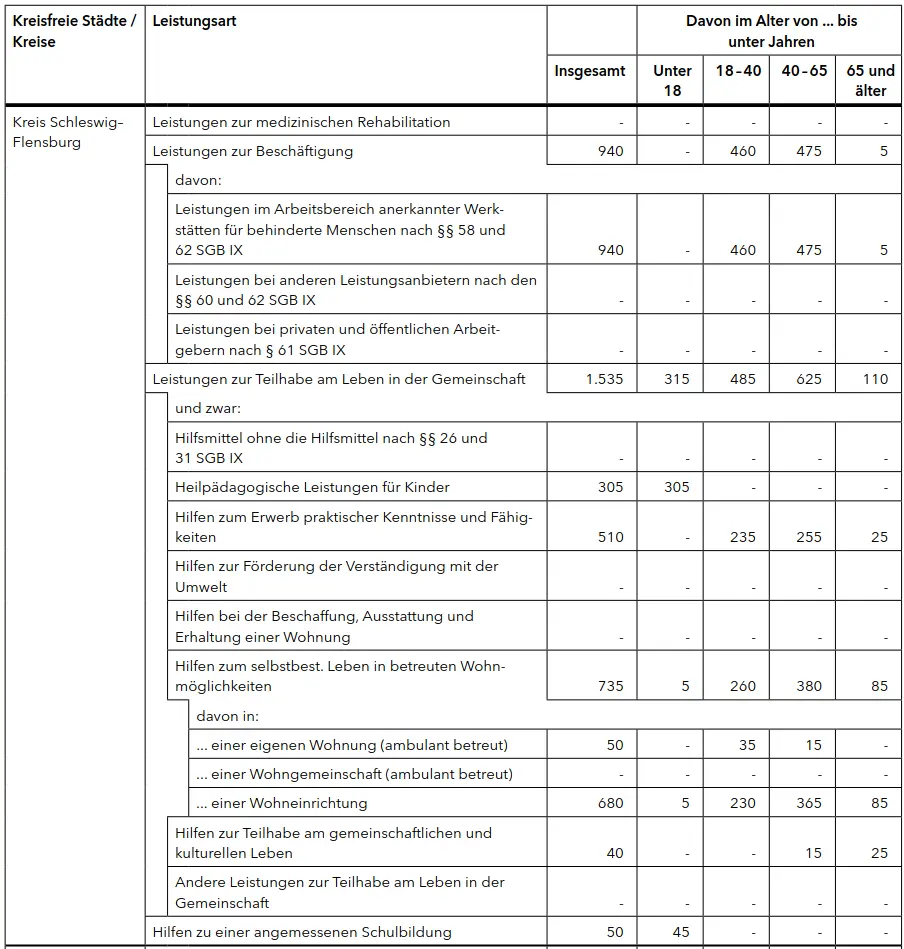
Mal wieder bin ich auf eine grafisch hübsch gestaltete Tabelle mit etwas komplexeren Statistiken gestoßen:
Ich frage mich schon seit längerer Zeit, wie man solche Daten gut maschinenlesbar darstellen kann. Hat jemand diesbezüglich einen Vorschlag?
Mal wieder bin ich auf eine grafisch hübsch gestaltete Tabelle mit etwas komplexeren Statistiken gestoßen:
Ich frage mich schon seit längerer Zeit, wie man solche Daten gut maschinenlesbar darstellen kann. Hat jemand diesbezüglich einen Vorschlag?
Vielleicht könnte man sowas in json oder yaml erstellen?
Die Frage ist am Ende immer wie man genau gut definiert. ![]()
Eine möglichkeit ist es für jeden Wert eine Zeile zu setzen. Da kann dann auch noch ggf ein Zeitbezug oder ähnliches rein. Dazu empfiehlt es sich für den Raumbezug (hier Kreis Schleswig-Flensburg) auch die ID mitzunehmen, dann ist es eindeutig worum es geht, auch wenn sich Kreisnamen ändern oder Schreibfehler drin sind, etc. Oder man zwei Datensätze zusammen führen möchte wo zwei Unterschiedliche Kreise vorkommen:
Datensatz A) Kreis Schleswig-Flensburg
Datensatz B) Schleswig-Flensburg, Kreis
Wenn beide eine ID haben, geht das zusammenführen super einfach.
| Index | Kreisschlüssel | Kreisname | Leistungsart Ebene 1 | Leistungsart Ebene 2 | Leistungsart Ebene 3 | Wertebezug | Werte |
|---|---|---|---|---|---|---|---|
| 000 | 01059 | Kreis Schleswig-Flensburg | Leistungen zur Teilhabe am Leben in der Gemeinschaft | Hilfen zum selbstbest. […] | davon in einer eigenen wohnung (ambul. […]) | Insegesamt | 50 |
| 001 | 01059 | Kreis Schleswig-Flensburg | Leistungen zur Teilhabe am Leben in der Gemeinschaft | Hilfen zum selbstbest. […] | davon in einer eigenen wohnung (ambul. […]) | Unter 18 | - |
Das macht die Tabelle am ende zwar sehr lang, aber gut für Maschienen lesbar, es lässt sich zum Beispiel sehr schnell dann ein Multiindex Dataframe in Pandas daraus bauen. ![]() Ich hoffe das hilft weiter.
Ich hoffe das hilft weiter.
Andromeda Berg
Open Data Manager BBSR
Im Umfeld von UN und OECD und des internationalen Austauschs wurde für solche Zwecke das SDMX-Format entwickelt. Ist für eine einzelne Tabelle vermutlich zu viel Aufwand, aber für größere und vereinheitlichte Datenbestände sehr mächtig. Am UBA wird das Format z.B. für den öffentlich verfügbaren Data Cube genutzt.